Data Access 数据访问类型节点之一 IO节点
前两章我们介绍了 KNIME 的基本使用、分析流程,并非常简要的使用了一些节点。我们还了解了节点的图示、颜色类别、端口类别、workflow 工作流、怎样提高工作流的可读性以及 metanode/components 和 Flow Variable 的概念。这些基础知识都非常重要,其中绝大部分内容通过长时间使用 KNIME 都可以掌握,只有 怎样提高 workflow 的可读性 和 模块化(metanode 和 components) 需要刻意练习才能掌握,而这两部分内容,也是 KNIME 水平从入门到中阶的必经之路。
下面我们介绍一下 KNIME 中的具体节点, 越熟悉这些节点, 那么就越容易完成我们未来的分析工作。原因也好理解, 如果我们知道了家里有铲子、改锥等工具, 那么一定会在不同的任务选取最合适的工具来提高工作效率. 在 Node Repository 窗格(默认界面的左下角窗格)中有很多节点,如果装了一些扩展的话,节点会更加丰富(比如图中的 Palladian 就是自行安装的扩展)。我们在这里将这些节点类型统一组织成了 Data Access 数据访问类型、Transformation 变换类型、Analysis & Data Mining 分析和数据挖掘类型、Visualization 可视化类型以及 Deployment 部署类型,这样在逻辑上将会更加清晰,也符合一般的数据分析的大致步骤。这一章主要介绍前三个部分的内容,后面两个类型的节点将会在后面的章节进行介绍。另外需要说明的是, 因为 KNIME 版本的升级变动以及每个人有可能安装了不同的扩展, 所以截图会有不完全一致的情况出现. 另外, 这里对节点的介绍只是对其关键特性或配置的介绍, 如果想要熟练使用这些节点, 还需读者朋友根据节点的重要性依次熟悉练习. 现在我们先了解下 Data Access 数据访问类型节点。
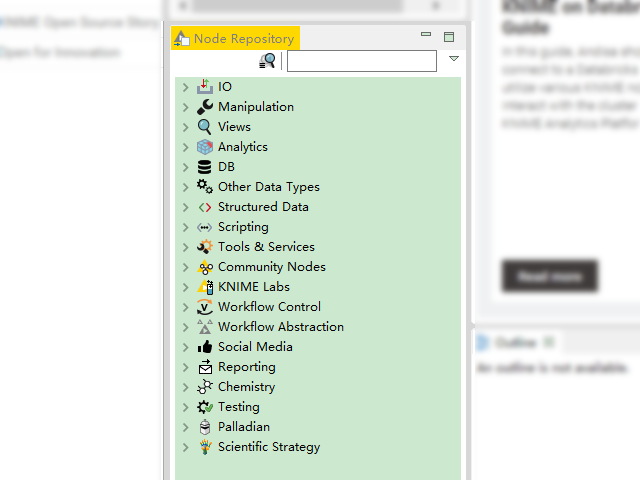
KNIME 的 Node Repository
Data Access 数据访问类型节点
Data Access 数据访问类型节点主要有文件相关节点、数据库相关节点、以及网页相关节点。其中文件相关节点中的 CSV 相关节点以及数据库相关节点,我们已经在读取数据源章节中有简要提及。除此之外,Node Repository 中的 IO 输入输出节点集合、Database 数据库节点集合、Tools & Services 中的部分节点,都可以归类到 Data Access 数据访问类型中。
IO 输入输出节点集合简述
IO 输入输出节点在整体上分为 Read、Write、Other、File Folder Utility 以及 Cache 几个部分,其中 Write 写操作的相关节点,虽然我们认为它是 Deployment 部署类型节点,但它们内容比较简单,而且和 Read 读操作节点有对应关系,也放到这里进行简要说明。
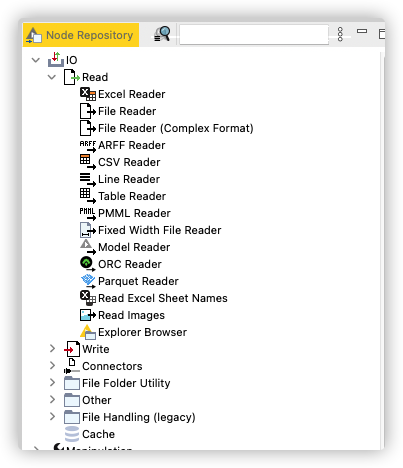
Node Repository中的IO节点集合
Read部分
对于Read部分,主要涉及到各种实体文件的读取。
对于 Excel 文件来说,如果你已经确定要读取 Excel 文件的哪个表,那么我们就可以直接使用 Excel Reader(XLS),直接配置节点即可,其选择和 CSV reader 的配置差不太多,除了一些标准的配置之外 -- 比如 Column Name 列名从哪里取、Row Id 行编号要不要自动生成等等,还有不少选项都集中在配置对于异常情况如何进行处理;如果我们需要将 Excel 中所有的表的内容都读取出来,那么可以尝试先使用 Read Excel Sheet Names (XLS) 读取 Excel 表名节点,读出这些表的名字,然后再设置一个循环,使用 Excel Reader(XLS) 将每个表中的内容读取出来,可参考下图结构。其中的循环节点和 Flow Variable 知识点我们将会在后面章节内容进行详细说明。
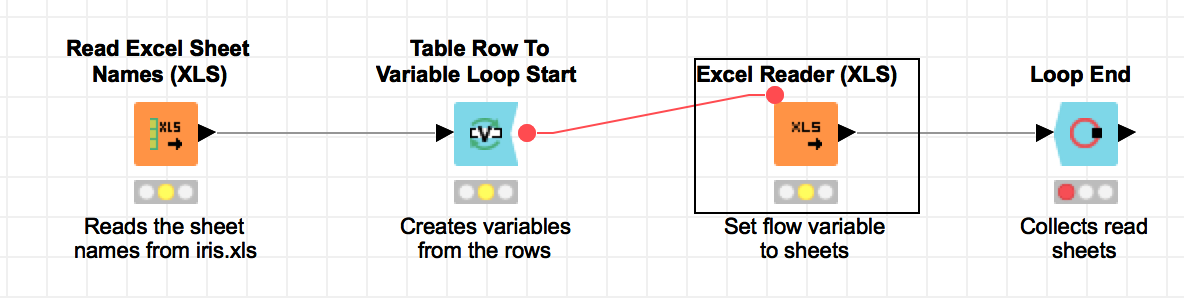
读取 Excel 文件中的所有内容
CSV Reader 之前有提及,在这里略去不讲。
File Reader 其实是一个通用版的文件读取工具,甚至可以用它来读取 CSV 文件,只不过配置项要更多一些。
ARFF Reader ARFF 文件读取. 此节点用的不多, 了解即可.
ARFF 是机器学习中的一种特定文件格式,这个格式主要是随着 Weka 软件发展出来的。简单来说,它除了记录具体的数据之外,还详细记录了数据的�格式、来源等一系列信息,对于经典的 iris 数据集来说,ARFF 就是这样记录的:
% 1. Title: Iris Plants Database
%
% 2. Sources:
% (a) Creator: R.A. Fisher
% (b) Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
% (c) Date: July, 1988
%
@RELATION iris
@ATTRIBUTE sepallength NUMERIC
@ATTRIBUTE sepalwidth NUMERIC
@ATTRIBUTE petallength NUMERIC
@ATTRIBUTE petalwidth NUMERIC
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
% The Data of the ARFF file looks like the following:
@DATA
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
.............
Line Reader 是用来将文件一行一行读出来的节点,特别像 Python 中的 readlines() 函数。
Table Reader 这个节点是用来读取 KNIME 自定义 Table 格式文件的(文件名以 .table 为后缀),这种类型的文件是 Table Writer 节点输出的。这个文件和 ARFF 文件的目的相同,就是在这个文件中,尽量的包含和这个数据文件相关的其他元信息(meta information),甚至标记出数据的颜色信息 -- 如果有的话,以及对数据文件进行压缩优化,以提升读取效率。因为是 KNIME 自己的格式,如何读写已经做了固定的约定,所以基本不需要做什么配置就可以使用,但唯一需要考虑的一点就是,如果要迁移到 KNIME 以外的平台使用,可能会遇到一些麻烦,但如果纯粹在 KNIME 中作为交换文件来使用,还是比较好用的。
PMML Reader 是用来读取 PMML(Predictive Model Markup Language 预测模型标记语言)文件的,这种文件主要是用来记录一些机器学习中的模型以及模型参数的。
Model Reader 是用来读 KNIME 自己定义的模型文件的,和 .table 文件类似,纯粹在 KNIME 平台中使用时会比较好。
Read Images 节点,可以通过输入的图像数据的 URLs,读出对应的图像列,用于后续处理。
Explorer Browser 这个节点主要是用来获得 KNIME Explorer 窗格中文件夹路径的,获得这些路径之后,后面的节点就可以利用获得的路径,进行读写等操作了。
总的来说,Read 部分,需要重点掌握 CSV 文件以及 Excel 文件的读取节点。除了上面列出的节点,如果想要读取 Google Sheets,也是可以的,只不过要安装相应的扩展,以及配置相应的网络环境。而这些 Reader 节点所对偶的 Writer 节点, 大部分选择都和 Reader 类的选项一致. 需要注意的一个选项是, 当重复写入一个文件时, 需要考虑是当作失败处理, 还是直接进行覆盖.
File Folder Utility 部分
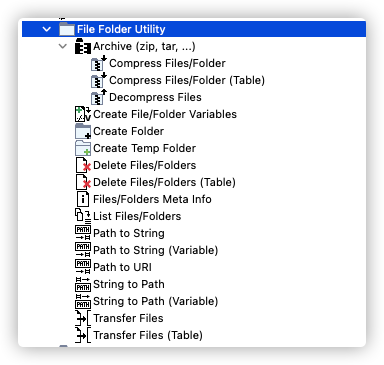
IO节点集合中的 File Folder Utility 部分
Archive 压缩打包相关节点,一般是配合多个压缩文件使用的。比如在一大堆的压缩文件中,我们可能需要按顺序解压压缩文件,然后再分析处理解压缩之后的文件,在这种时候,我们就需要ZIP这个节点了。需要注意的是,ZIP相关的这两个节点,支持众多的开源压缩方法,比如tar.gz, zip等,但是对于闭源的rar压缩包,它们是不支持的。
Create Temp Folder 可以用来生成临时目录,和 Linux 系统编程中的mktemp的功能类似,在某些特定情况下会使用到,比如我们想要临时生成一个 sqlite 文件进行读写,但又不想永久保存这个文件,那么就可以使用这个节点来建立一个临时目录存放这个 sqlite 文件。除了生成临时目录之外, 还能生成一些在这个文件夹下的文件路径变量, 而这些路径变量, 就可以使用 xxx writer 节点进行写操作了.
List Files/Folders 作用是列出所给路径下有哪些文件或目录。比如需要读取一个文件夹下所有的 Excel 文件,那么就需要用到这个节点了。
Create Folder、Delete Files、Transfer Files这几个节点的名字含义比较明确了, 分别是创建目录、删除文件、传输文件(复制移动等),不再赘述。
Files/Folders Meta Info 节点,可以列出相应文件或文件夹是否存在、大小、权限等相关内容。
Path to String 或 String to Path 等相关节点. Path 是 KNIME 中的一种类型(新的类型), 当使用 flow variable 流变量时, 有的位置需要填写 path 类型的变量, 如果是 string 字符串类型的路径名, 是不能使用的. 这一类的节点就是在做这两种类型之间的转换, 有时还会需要和 URI 直接进行转换. URI 参见之前的介绍.
Other部分
IO节点集合中的 Other 部分
Binary Objects 二进制类节点. 其中一个使用场景是配合数据库使用,比如我们通过数据生成图片,然后把图片转换成 Binary Objects,再将 Binary Objects 存放在数据库中。
URI 类的节点。URI 是 uniform resource identifier,统一资源标识符的缩写。这个我们在之前有具体的介绍。URI这几个节点,在我们进行路径的各种操作时,就会需要它们。
Data Generator 节点可以按照要求(比如生成数据的中心、标准差、噪声数据等)生成一些随机数据.
Create Table Structure 可以生成一个没有数据的表结构,主要是配合 Concatenate 连接节点在处理不同表结构的时候使用的.
Send Email 发送邮件节点. 在长时间处理数据之后, 可以使用这个节点进行通知相关人员, 或周期性的运行工作流, 通过邮件通知结果, 非常方便.
Extract System Properties 和 Extract Context Properties 就是获取一些系统信息,以及一些当前工作流的信息了。比如在 Windows 环境中, 我们想要在当前用户的桌面上生成一个文件, 那么就需要获得当前登陆的用户名了, 这样可以保证同一个工作流可以在不同人员的机器或账户上正常使用.
Find MIME-Type 节点以及 List MIME-Types 节点,主要是配合 HTTP 使用的,一般在文件上传时,需要在 http request中写上 mime type 信息。
Table Creator 其实相当于一个小型的 Excel,打开之后直接编制数据。
Variable Creator 流变量创建节点. 使用场景有限. 一般情况下, 会使用带有交互性的 Configuration 或 Widgets 类的节点来创建流变量节点.